整理一下leetcode里面关于 2sum 3sum 的几个问题,后面还补充了几个two pointer的其他问题,主要是longest sub str with at most K distinct characters的一系列问题。关于 hashtable 以及 two pointer的应用,由于在实现上不像树、图那些在结构上比较复杂,大多是灵光一闪,或者是绕一两个弯就能想到的,面试也是各种常考,应该是要掌握好的一类基本问题。
通常思路上而言,two pointer的题目就是把O(N^2)的时间算法简化到O(N)或者O(M+N) (when there are two input arrays)。主要的模式有两种,一个是快慢指针的类型,另一种是指针从两边往中间走的类型。
这一部分题目关键是掌握几种常见的问题背景,因为每一种背景可能有一些隐藏的信息,比如container with water 11 和 42 都是从两边往中间走。因为当前container的长度是最长的,如何后面的container的高度比当前的短的话,就不可能得到更大的容积。
移动指针的时候常用的套路就是每次移动之后再进行比较。一般是一个for loop + while loop 外层for loop 有O(N)的复杂度,内层如果是for就成了O(N^2)的算法了,一般内层就是一个while loop 可以trim 掉很多的组合。while (i<n) { do sth; i++} 这样的操作本质上和 for(i=0;i<n;i++) {do sth} 是一样的操作。或者就是另外一种,用一个while(i<j)的loop,每次往中间移动一个元素。
还有常用的套路就是使用map,特别是对于distinct elements以及2/3 sum这样的类型的题目。subarray sum 之类的题目常常用到的技巧是prefix sum 比如 560 用到了prefix sum 以及 map 并且还有一些 2 sum 的技巧。
Pointer from two sides
11 Container With Most Water
这个就是指针从两边往中间移动的题目,核心的操作是找 max(h[i],h[j])*(j-i) 所以就是移动左边或者右边比较小的那个指针的位置,固定一边,移动另一边,才有可能找到更大的组合的可能。因为每次while循环开始的时候就认为假设元素的位置已经移动了,或者是系统的状态已经更新了,所以要在这里updata metadata。
class Solution { |
One good explanation is that, since we move from largest distance to the smallest distance, once the h[i]<h[j], the h[i] will not be used in future cases when there is less distance. (even if we get higher number of the right value, the min value is still h[i], since the current dist is the largest one we iterate, the further container volum can not larger than current one) in current dist, there might exist some combination larger than (h[i],h[j]).
42 Trapping Rain Water
这个是前一个题目的升级版,关键是首先弄清楚所要search的对象对于每个slot是 min(h[left bound], h[right bound]) - h[curr hight] 这一点不是很容易想到。
具体框架与前面一个题目类似,在比较的时候,比如更新到某个位置的时候,要考虑清楚移动的原因,比如h[lb]>h[rb] 这个时候对于右边的当前元素来说,如果lb 和 rb 中间有更高的wall,那对于右边的元素来说,wall的位置是h[rb] 因为这个位置的元素限制了water的高度。如果它们之间都是比较低的wall的话,那water level的位置还是h[rb],因为这个时候本身左边的wall的高度就是更高的。
所每次移动的时候要随时更新left tall wall and right tall wall 的位置。因为每次不是更新左边就是更更新右边,所以当前元素的位置也要随时更新。相比起上一个题目,这个难点就是需要维护更多的metadata。
class Solution { |
This is a good explanation (really good) for this question
https://www.youtube.com/watch?v=C8UjlJZsHBw
There is even more complicated question, such as this: Trapping Rain Water II, however, it seems that it is not the simple extension from 1d volume water soluation, checking more details here, even there is similar backgound, but the solution becomes different. (it becomes a BFS searching, searching cell from the current known lowest position)
125. Valid Palindrome
The simple idea of two sided pointer that shows basic idea, there is no compilated data structure or background knowledge used in the iteration operation.
class Solution { |
There are several similar question based on string using same techniques, such as 917.
917. Reverse Only Letters
Figuring out the rule is important, when there is non english letter, when just skip it in one side. So there are two small while loop in the large while loop two skip associated elements. Be careful when checking the index such as i<j
class Solution { |
Other simple cases
977 is straightforward, when there is faraway from the center position, the square value is larger, so just compare the square of i position and j position continuously.
Pointer of two arrays
455. Assign Cookies
Using two pointer for each input array, the outline of code is really standard, just compare two element for each iteration, the important things is to figure out the pointer movement rules for each iteration. For this question, after sorting the input elements, we can get some extra benifits, when satiafaction level does not satisfy current child, we just need to move to next cookies, since the array is sorted. We do not need to need further comparision of current cookie’s satiafaction value with higher children’s satiafaction value.
class Solution { |
925. Long Pressed Name
Be careful about the edge cases, for example, one string completes the iteration but the other one does not compelete the iteration.
class Solution { |
986. Interval List Intersections
The framework is a common one for this, the a little bit complicated part is to consider all kinds of situations each time when deciding how to move, there are two nonoverlapping case, two partial overlapping case and two fully overlapping case.
class Solution { |
K sum
two sum (1)
Given an array of integers, find two numbers such that they add up to a specific target number.
The function twoSum should return indices of the two numbers such that they add up to the target, where index1 must be less than index2. Please note that your returned answers (both index1 and index2) are not zero-based.
You may assume that each input would have exactly one solution.
Input: numbers={2, 7, 11, 15}, target=9
Output: index1=1, index2=2
解法一
由于要先定义好结构体,把index和value的值都存入进去,相比解法二直接使用map代码要稍微多一些,时间复杂度要稍微高一些。
- 定义Node接口体 对生成vectorvnode对其进行初始化赋值
- 对vnode 根据每个元素的value值 进行vector排序
- 采用左右两个指针 向中间靠 发现符合 node1.v+node2.v=target 的两个元素
- 和大于target则右指针左移 和小于target则左指针右移
- 取出其index值,index1=min(node1.index,node2.index) index2=max(node1.index,node2.index)
typedef struct Node{ |
解法二
利用map的特性,代码简单不少,实质上是很好地利用了map的空间和时间特性。
- create map < int,int > the lenth of vector is len 其中key值为array中的数字的值,value值为该数字在序列中的下标
- 遍历 vector 每次 keyb= nums[i] keya = target - keyb
- 如果keya不在map中,将当前的元素插入到map中,map[keya]=i
- 否则,返回 index1=map[keya] index2=map[keyb]
class Solution { |
注意特殊用例,就是可能出现像 [ {0,4,1,0},0 ] 这种情况,所以不能在开始的时候就把vector中的元素全部放到map中再对vector遍历,要一边遍历vector一边把其中的元素存到map中。
167. Two Sum II - Input Array Is Sorted
Since the input array is sorted, there are some benifits using the two pointer from the both side. When v[i]+v[j] > target, any value at the right side of j, is more larger, so we decrease j. Similarly, when v[i]+v[j] < target, using any value at the left side of i is less than target, so we increase i
class Solution { |
3Sum(15)
基本上是上一题目的基本升级版
解法一
采用两指针的思路,a+b+c=0实际上就是求,a+b=-c , 比上一个2sum的问题多需要考虑的一个地方就是,需要考虑多组不同的解,以及去掉重复的解。大致思路都是基于排序,之后再遍历,在每个元素后面的序列中找两个数字的和为-current的组合。如果不进行优化,肯定会超时的,优化的方面参考了这个
- 整体思路是在2 sum 的基础上多进行一层循环,排序之后遍历每个元素,然后对剩下的部分进行2sum的subroutine。
- 一个是在遍历的时候 元素重复了就直接跳过
- 还有一个是 发现一组解之后 指针left right就要向右侧移动,把相同的元素都跳过,就是helper函数中的那两个while循环 但还是要保证 left < right 并且在access i+1 和 j-1 之前要验证一下access的位置是否valid。
其他的细节问题,vector嵌套以及声明的时候在vc6.0中注意空格 ,比如 vectortemp 否则会编译错误,虽然老生常谈的了,还是被坑了。每次temp vector存数据的时候,先clear一下,貌似之前的记录还在。
class Solution { |
解法二
使用map也是可以的,只不过key value的值与上题不同,value不是存储元素所在的位置。这个算法写出来比较容易,理解上有点困难。
比如 序列{-4,-1,-1,0,1,2} 遍历到-4的时候,从后面的元素开始看,需要在后面的元素中找两个元素,使得 a[i]+a[j]=4 才符合,-1+5=4 所以 map[-1]=4 同理 ,map中依次存入 (4+0=4) map[4]=0 (3+1=4) map[3]=1 (2+2=4) map[2]=2 遍历所有的key值 若同时存在 map[a]=b 以及 map[b]=a 说明 a b 两元素同时都在这个序列中,并且a+b=4。
对于去重的话,第一次遍历的时候,后面一个不等于前面一个,第二次存入map的时候,如果key值已经存在,并且 key==value 就是三个元素中,有两个是相等的。类似 (2,-1,-1)这种
还有个问题没解决,如果不对原始序列排序的化,去重的问题要怎么考虑?这里还没解决,排序的话有超时了
这个是超时的:
class Solution { |
3Sum closest
Given an array S of n integers, find three integers in S such that the sum is closest to a given number, target. Return the sum of the three integers. You may assume that each input would have exactly one solution.
For example, given array S = {-1 2 1 -4}, and target = 1. |
就是三个数相加,和不断接近目标数,其实和上一个题目的思路有点类似,在求和的过程中,不断更新,由于题目中已经保证了有唯一的一组解,就保留最接近的那种就可以了。貌似很容易,代码也很简单,但是最后还是参考了别人写的。问题实质是转化为,如何在一个有序序列中找到a[i]+a[j]=sum 使得 abs(sum-target)的值最小,这个还是基于两个指针的策略,但是要好好整理一下。
- 输入序列本身是有序的序列,这个是保证2 sum 类的题目可以进行两边指针往中间遍历的前提。
- 遍历这个有序序列(从0号位置到len-3号位置)跳过重复的元素,设置left right两个指针, left 位置从当前元素的下一个开始一直到最后一个元素的位置为止
- 在每一个subroutine里寻找符合条件的thee sum. temp=a[curr]+a[left]+a[right] closet=temp
- while (left<right) 更新 temp, 具体操作如下
- if temp == target 返回 temp a[left] a[right] 是所需寻找的值
- if temp < target left ++ 如果 abs(temp-target)<abs(closet-target) (说明当前的 three sum的temp结果比记录中的还要更接近target,之后时候更新记录中的位置) closet=temp 所有的情况都考虑的话可以有 left ++ / — right ++/— left — 没有意义,因为当前已经比较小了,想要找更大的元素只能left++。为什么不进行right++?因为right 指针所在的位置是从最右边开始往左边走的,当前right元素右边的可能情况都已经考虑过了,关键的几个细节一个是序列本身有序,一个是left right指针是从序列的两边往中间走。
- if temp > target right– 如果 abs(temp-target)<abs(closet-target) closet=temp
最后返回closet
注意closet的持续更新,每次都要用temp-target和closet-target来进行比较,之后更新closet,有需要的话,还需要及时记录当时的left和right的位置,因为不可能靠移动一边的指针找到距离target最近的sum,总之这里要好好体会体会并且记会,属于基本套路了。
还要注意的是init的minValue不需要弄成INT_MAX,只需要弄成一个比较大的数字就好了,因为在比较的过程中还会进行 currsum-target的操作,如果弄成INT_MAX就容易溢出产生错误。
For the time complexity, it is still O(N^2) since the actual iteration opertaions is O(N-1+N-2 … 1)
class Solution |
这个是更简易的一个版本, 在subroutine中没有进行优化
class Solution |
3Sum smaller
这个题目开始收费了,参考了这里(http://likesky3.iteye.com/blog/2236385):
Given an array of n integers nums and a target, find the number of index triplets i, j, k with 0 <= i < j < k < n that satisfy the condition nums[i] + nums[j] + nums[k] < target.
For example, given nums = [-2, 0, 1, 3], and target = 2.
Return 2. Because there are two triplets which sums are less than 2:
[-2, 0, 1]
[-2, 0, 3]
大致分析一下,要求多组解,大致框架应该与上面的相同,先排序,再遍历(主要目的是固定一个数),再两指针选择。关键是两指针选择时候的技巧性:
- while (i<j)
- sum3=nums[i]+nums[j]+num[now]
- if (sum3<target) ,由于序列已经是有序的,这个时候 nums[now]+nums[i]+nuns[j-1] 、nums[now]+nums[i]+nuns[j-2]… nums[now]+nums[i]+nums[i+1]这些组合都是符合要求的,所以符合要求的组合数目要加上 j-i 。相加之后让i后移一位。
- if (sum3>=target) 这个时候就是往小移动,即 j–- 还要处理下重复的情况 如果 num[j]=nums[j-1]的时候 也前移一下 放在一个while循环中 始终保持 i<j
4 Sum
Given an array S of n integers, are there elements a, b, c, and d in S such that a + b + c + d = target? Find all unique quadruplets in the array which gives the sum of target.
Note:
Elements in a quadruplet (a,b,c,d) must be in non-descending order. (ie, a ≤ b ≤ c ≤ d)
The solution set must not contain duplicate quadruplets.
For example, given array S = {1 0 -1 0 -2 2}, and target = 0.
A solution set is: |
背景与2Sum的形式一样,只不过由两个数变为4个数。最容易想到的一种就是转化为3Sum最后再转化为2Sum来解决。就是把外面的一重循环变成了两重循环。其实就是注意几个核心的操作,基本的框架是两指针,去重的操作怎么来,第一次循环的时候去重,用两指针寻找的时候也去重,一组解的时候怎么弄,多组解的时候怎么弄,还有vector的基本操作,比如排序这些,这些都弄好了,解决起来就比较容易了
class Solution { |
Substr/sub sequence related questions
这个类型的问题的关键有两个一个是使用two pointer start from the same position, 另外一个就是using other metadata wisely.
metadata可能是map或者是其他的数组(比如Leetcode 3)
因为涉及到distinct element的问题,如果map中对应元素出现的frequency为1,那就是distinct的。map中的元素的个数可以用来判断subarray的长度,掌握好这些要点再解决起来这一类问题就会容易一些。关键是掌握如何描述对应subarray的性质。
674. Longest Continuous Increasing Subsequence
This is comparatively simple, the subsequence is continuous, we just check it gradually, if the subsequence continue increase, we increase the subsequence len, otherwise, we set it back to 1, and the subsequence then start from new value. We keep monitor the length of subsequnece and remember the largest one.
class Solution { |
300. Longest Increasing Subsequence
Compared with previous one, this subsequence can be discontinuous. But the order of element is not changed, which means if element b is at the right side of the element a, element b continuous stay at the right side of element a.
This can be a classical one, it might be easier to come up with the dp based solution, and consider which element can contribute to the current answer. So for each new element, we might need to check all existing history before it to see the previous records that end with that. In that case, we can use the key of map as the value of the previous element, and the value of the map is the length of subsequence end with corresponding element. After finding a largest one, we can than add 1 based on that
class Solution { |
However, it might be convenient to use a dp array to replace the map, the key of the map can be the index of the dp array.
class Solution { |
The next level of optimization is not easy to come up with. Instead of using linear searching in the second loop, we can try to find the associated element by binary search. Using divide and conqure to find element that is less than the current value. We need to dynamically update the dp array (The reason we can do this is that current solution is the sub structure of the end solution).
class Solution { |
128. Longest Consecutive Sequence
Be careful about the subset, substr or sub sequence. Understanding this question is a little bit tricky, we actually get a subset from the original sequence, the element in that subset can construct the increasing sequence, in the constructed sequence, the difference between each element is 1.
The original way is sorting and then ofter sorting, we basically change it to 674, but sorting need O(NlogN) time. The question requres O(N) time
This is a solution based on set, check this video to get more ideas, the key point is to find the element which can be the start position of a new array and try to explore the maximal length it can reach by adding one gradually.
class Solution { |
Another approach is firstly use the previous subroutine (300) and then merge the results. If value map[nums[i]] exist, and its assocaited value is len1 = map[nums[i]], then we try to look at if nums[i]-len also exist in map, if it exist, and the value is len2, then the element end with nums[i] is len1+len2, then we also move to the next element in map that is larger than nums[i]. Similarly, we can continue merge and find the largest one. By this way, we actually look at the ending of the subsequence and check the largest length it could be.
3. Longest Substring Without Repeating Characters
Given a string, find the length of the longest substring without repeating characters. For example, the longest substring without repeating letters for “abcabcbb” is “abc”, which the length is 3. For “bbbbb” the longest substring is “b”, with the length of 1.
根本上讲还是两指针的问题,只不过两个指针在开始的时候是在同一个位置上的。需要额外的空间就是exist数组,用来存储该元素是否存在过。以及position,用来存储上一次出现的位置。注意还有可能是其他的字符,所以要0-128的存储空间,主要流程如下:
- 一个while循环中 两个指针l,r初始位置都是0,或者用一个for loop 遍历right指针
- 当前字符没有出现过 ,r指针右移,更新position。
- 当前字符已经出现过 ,更新长度 ,记录position的位置,l指针移动到上次出现位置的下一个。注意限制条件,要上次的位置大于l的位置才能更新,比如 “eccebaad” 当遍历到第二个e的时候,position中记录的last位置为1,但是这个时候left指针已经移动到了c的位置,这个时候就不要更新了,不需要让left指针再往回退了。
- 最后r指针都向后移动一位。
class Solution { |
Longest Substring with At Most Two Distinct Characters
Given a string, find the length of the longest substring T that contains at most 2 distinct characters.
For example, Given s = “eceba”,
T is “ece” which its length is 3.
注意与上一个题目的区别,上一个题目是没有一个重复的元素的最长序列,这个是说最长序列中允许有两个重复元素,注意对两种序列描述的时候的区别。
这个题目改收费的了,从网上看到了别人的解答,这个问题最一般的情况是 at most K Distinct Characters。整个框架还是一样的,说白了就是,两指针从头遍历,有点滑动窗口的意思,不断调整两个窗口的边界。此外还需要一个存储出现次数的count数组,关键是存储position的策略,比如 “ececebad” 这种,当k=2的时候,当第三次到e的时候,l指针应该到第一个e后面的一个位置。这里就不太好存储位置了,因为如果有第四个e的时候,此时l要到第二个e的后一个位置,所以可以参考这个,对于k个位置的时候,要注意对k进行适当的分类。比如比如k<0,以及s.size()<k 这些情况要怎么处理。具体可以参考这个(http://blog.csdn.net/martin_liang/article/details/45648985)
当count数目大于K的时候,l就向右移动,一直到对应的元素出现位置,之后count-1,之后l移动到这个元素的下一个位置就更新完成了,不用一个专门的position来存储位置信息。
或者用一个map来存储,key是对应的元素值,value是这个元素出现的次数。简化之后可以使用string来存储。The index of this question is lintcode 928. Be careful of processing the deletion of the map. If the current element does not exist after moving the left pointer, then removing it from the map. Using the size of the map to adjust the number of distinguished elements in the substr.
class Solution { |
Longest Substring with At Most K Distinct Characters
Lintcode 386, the general case for the previous one.
class Solution { |
992. Number of subarray with exact K different elements
This is a really tricky one, instead of computing the substr with k different elements direactly, we use another subroutine. The number of substr that have most k distinct elements. If we call this substr as AtMost(k), then the number of subarray with exact k different element equals to AtMostK(k)-AtMost(k-1)
One easy task for this question is to consider how many subarray is added once we add a new element. From right side to left side, assuming left pointer is i and right pointer is j, assuming element at j is new added one and satisfy the condition of subarray, the new added number of subarry is j-i+1.
class Solution { |
This is a good explanation about this question
https://www.youtube.com/watch?v=akwRFY2eyXs&t=2s
560 Number of subarray with sum equals to K
This is a good explanation, this is a good question
https://www.youtube.com/watch?v=HbbYPQc-Oo4
The naive strategy is to go through all possibilites of the array, there is O(N^2) combinations, for each combination, then accumulate the element from i to j which need O(N), so the total time complexity is O(N^3)
When there are reqquirements for computing the sum of a subarray, an important trick is to use the prefix sum, which decrease the O(N) to O(1) for computing the subarray, subarraySum(i,j)=PrefixSum(j)-PrefixSum(i-1). By this way, we can decrease the time complexity to O(N^2) based on prefix sum.
It is easy to figure out this is the 2 sum question based on the prefixsum, if T = subArraySum(i,j) = PreSum(j)-PreSum(i-1), we can use a frequency map. For each time we go through an element, we want to find T= x - Psum(curr), x is an unknown variable (we need to store this as key value of the map), if the current position is the left start of an array that satisfies requirements, we can definately find an Psum(i) = x in the subsequent iteration of the array. Then we can use a frequency map to store this relationship, let map(x) = map(x)+1. (map(x) is zero if the x is not exist previously.) So each time we find a new go to a new element, we can get the PreSum for current position and look at this frequency map, if there is specific key, it means that current element can be the right side of specific subarray. The key in the map represent the required a PreSumValue to construct a subarray that satisfies condition, the value in the map represent the number of element that require this type of PrefixSum. This question only ask us to return the number of subarrya, if it ask as to return specific i and j position, the value of map should be a vector since there might be multiple elements require same PrefixSum.
The code is simple, but the ideas behind it is definately not simple.
class Solution { |
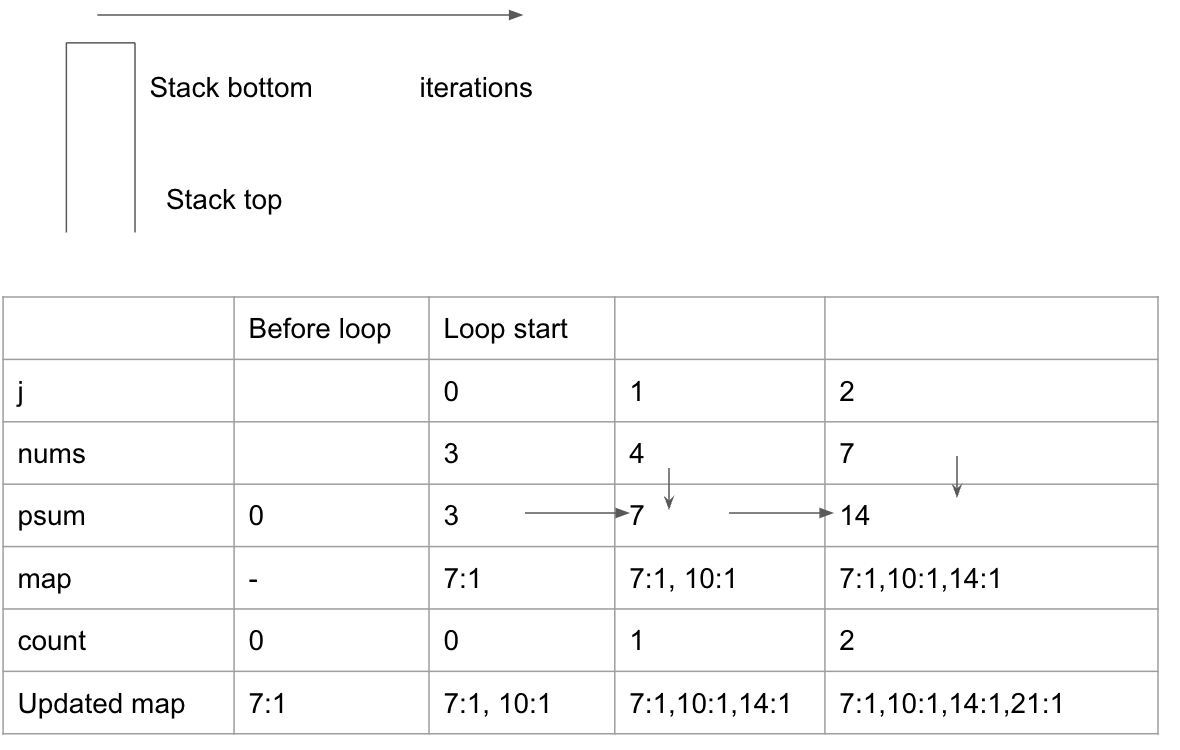
This figure illustrates a good habits to debug and analysis how the algorithm work in mind. The vertical line represents the stack from the bottom to top, the horizental line represents the steps, such as before while loop and after while loop, this framework can clearly list value of key elements at each step, and help us to debug code easily.
For example, by analysing the depedency, we can see that we only use one variable to keep the prefixsum.
53. Maximum continuous Subarray
The idea is to maintain the left side pointer and right side pointer to make sure there sum is the largest one. The O(N) idea is not easy to come up with (but it is actually a pretty straightforward one). We just need to figure out the principle to update the left and right pointer. For updaing the right pointer, for a new element, we may try to add it to our subarray, when the current sum is larger than record, we update right side index. If we find that after adding the value to the array is not good compared with using current value as a new subarray its self, namely the currSum<num[i], we can update the left side pointer and let it starts from the element of the position i.
class Solution { |
It might interesting to go from scratch to see what if we can not come up with previous solutions and how we go from simple to compilated case. (This is a sample question in 计算之魂)
Naive solution, how many combination of left pointer and right pointer, then computing each sub sum and find one that is largest. O(N^3)
We may come up with a prefix sum data structure to help to find the subrange between i and j, by this case, we can decrease time complaxity to O(N^2)
The binary search solution is actually easy to come up with but hard to implement and thinking clearly. The correct solution can be at the left side of the middle, right side of middle position or the middle is in that range. The clever part is that if we know the middle element is in the range, then we go through from mid-1 to l and mid+1 to r, and keep updating the l label and right label when the the sum is updaetd, then we can get the correct new range. The time complexity becomes O(NlogN) in this case.
This is one sample answerclass Solution {
public:
int helper(int l, int r, vector<int>& nums) {
//std::cout << "l " << l << " r " << r << std::endl;
// edge case
if (l == r) {
return nums[l];
}
int mid = (l + r) / 2;
// mid in solution
int maxmidSum = nums[mid];
int tempSum = maxmidSum;
// range left
if (mid - 1 >= l) {
for (int i = mid - 1; i >= l; i--) {
tempSum = tempSum + nums[i];
maxmidSum = max(tempSum, maxmidSum);
}
}
// range right
if (mid + 1 <= r) {
tempSum = maxmidSum;
for (int i = mid + 1; i <= r; i++) {
tempSum = tempSum + nums[i];
maxmidSum = max(tempSum, maxmidSum);
}
}
// mid element not in solution
int maxLspan = INT_MIN, maxRspan = INT_MIN;
if (mid - 1 >= l) {
maxLspan = helper(l, mid - 1, nums);
}
if (mid + 1 <= r) {
maxRspan = helper(mid + 1, r, nums);
}
return max(max(maxLspan, maxRspan), maxmidSum);
}
int maxSubArray(vector<int>& nums) {
int size = nums.size();
if (size == 1) {
return nums[0];
}
return helper(0, size - 1, nums);
}
};
The linear based algorithm is based on greedy strategy(https://blog.csdn.net/Fuyuan2022/article/details/125664402)
