Try to disucss an example of the task based thread pool, and the case discussed here is the argobot (Argobots: A Lightweight Low-Level Threading and Tasking Framework)
the general strategy is the pthread, there are all kinds of tools that help to build the thread pool based on the pthread.
some prerequest concepts
system level thread vs the user level thread
This doc provides detiled explanation that compares the user level and system level threads, pay attention to the benifits disadvnatages.
The main benifits of userlevel thread is the speed, since it avoids the system call compared with the pthread. The disadvantages is the potential conflicts with the os thread scheduler, since for the os, there is only a one thread single process. It needs to be adjusted wisely to make the runtime scheduler fit with the process’s scheduler.
the typical states of the process
here are some detailed explanation
https://access.redhat.com/sites/default/files/attachments/processstates_20120831.pdf
and
https://medium.com/@cloudchef/linux-process-states-and-signals-a967d18fab64
we may neglect the sleep mode sometimes. When we execute the system sleep call and the I/O status, the process will be in these sleep states.
if the cpu is used when there is sleep or I/O
although there is time elapse, but the cpu is not used (or trivial cpu is used for scheduling or state change). This is related with the previous concept. When the sleep is called, the process change to a sleep mode. In particular, since the process can be waked up after the sleep finish, so when there is sleep call, it is in the interruptible sleep mode. But for the I/O, it change into the uninterruptible sleep mode while waiting for the result, they will wake up with when the operation is ready.
there are some online discussions realted with this:
https://unix.stackexchange.com/questions/22886/do-sleeping-processes-get-the-same-cpu-time
Attention! in some evaluation works, we may tend to use the sleep as the synthetic analysis, and we should consider it carefully in this context, although time is elapsed in this cases, but the cpu resoureces is not used, therefore, the results might not be that much convinced enough, it might be better to use other workflods, or consider the synthetic cased based on particular context.
how the sleep is implemented
this is an straightfoward explanation
https://stackoverflow.com/questions/1719071/how-is-sleep-implemented-at-the-os-level
The core concepts is to maintain a queue by higher level menager (for the os-level thread/process, the higher level manager is OS, for the user-level thread/process, the higher level manager is the runtime), then the higher level menager just check the element in the queue, when the sleep time is finished, then allocate resource to the thread.
Another strategy is to do an active checking, such as polling, in this way, thread is still in active state, but it is not efficient enough. One deteailed explanation is
http://www.gerald-fahrnholz.eu/sw/online_doc_multithreading/html/group___grp_condition_variable.html
the condition variable shares the same idea with the sleep, it can be used to implement the sleep in the runtime. The underlying implemetation of the sleep is the event driven paradigm based on the siganal. When the condition is satisfied (such as time finish), the associated thread is triggered and the state is changed based on the signal notification.
oversubscribing and performance
Based on this early stage work (https://crd.lbl.gov/assets/pubs_presos/ovsub.pdf), Oversubscription on Multicore Processors, for the evaluation of this work, it is based on the MPI+Pthread. It looks that the benifits acquired from the oversubscription depends on types of jobs. If we consider it intuitively, when there is IO or sleep in the task (the task is not fully computation intensive), there is always some benifits from the oversubscription, since the CPU can be fully utilized.
However, when we use thread pool, we may use the pthread as the manager thread, in that case, we just need to make the size of the pthread of manager thread equals to the number of the os-level thread. And then put more tasks in the task waiting list associated with each manager thread, and we do not the subscription of the os-level thread in that case.
This is a kind of the latest research in this area (https://www.bolt-omp.org/), when the OpenMP is integrated with particular thread pool, based on some optimization strategies, the performance can be further improved. It is interesting that the algorithm such as bipartition used to acclarate the bcast is also used here to improve the scalability.
argobot example
The argobot is a lightweight thread pool that provides user level threads. Details can be found in related paper (https://www.argobots.org/). This is the API for the argobot framework (https://www.argobots.org/doxygen/latest_dev/modules.html)
The associated c++ binding can be found here (https://xgitlab.cels.anl.gov/sds/thallium/-/tree/master/), and we just look at several examples from the perspetive of the programming.
Evaluation
multiple os level threads os-level sleep
This is a kind of weird operation actually, since the subscribing of the os-level thread will increase the overhead. Although we can do things like this, it is not a recomended way.
For the first experiment, we try to call system level sleep, we use 4 cores and start one process, the number of the total task is fixed as 128, every task will execute sleep(2.0) system call. The effect may similar with using the thread pool based on Pthread.
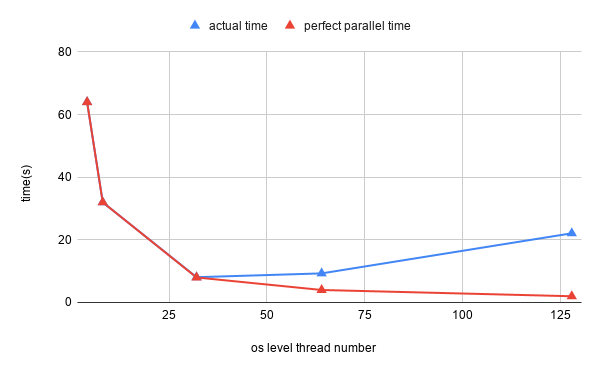
When there is 4 os-level threads, the sleep will called in system level, the whole os-level thread is transfered to the sleep states, since we only have 4 thread, the total execution time is 2*(128/4)=64, this thing is still true till the 32 threads. If there is no overhead of thread switching between cores, there are more benifits when we use more threads, however in this case, when the thread number is larger then 32, the execution time increase, this is because that the overhead of switching the os-level threads outperform the benifit of time saving from the multiple os level threads. Since we only have 4 cores here, after a specific point, such as 32 here, the overhead will increase. We may tend to ask a question, why it is 32, not 4 ? since we only use 4 cores. This might becase the task we used here is just sleep, which use trival cpu time, therefore, we can make more tasks to run in parallel without obvious overhead. If the task is fully cpu intensive, the oversubscribing of os level threads could not bring extra benifits.
core equally os level threads with user level sleep
It is obvious that use the system level sleep is not efficient, for the user level thread we discussed above, when we use the one os-level core to support multiple user level sleep, we do not use the system sleep call. In this experiment, we use 4 cores and 4 os-level threads (ES for the abstraction of the argobot), then we put task into the task pool (a list), different tasks will be scheduled onto the coresonding os-level threads. In this way, the runtime will be the “god” or the manager for the tasks, the sleep operation can be implemented here (which is similar with the way implemented by the OS, but in the different abstraction layer). We may still check the task list, when their sleep time is finished, the manager schedule it and bind it with the os level thread. In this way, we may not need to do the OS level system call.
| task number | 128 | 256 | 1024 |
|---|---|---|---|
| execution time | 2.0016 | 2.0021 | 2.0080 |
We tasted 128, 256, 1024 task, the time caused by the sleep is trivial, compared with the previous case, there are huge benifits here, and more cpu usage efficiency. Since based on runtime implementation, there are few chance to let OS level thread to become idle, the process will always at the running or runnable states.
We may consider this like a company, there is a director and particular manager for each section. Without the runtime, we may ask direactor for everything, the whole system may not run fast. With the runtime, it just seems that we add several particular manager, if a thing can be processed by a manager (such as task sleep), we do not need to bother the director, the whole system will run faster in this way.
for the compute intensive tasks
For the compute intensive tasks (we just use a while loop and let is run particular iterations), when we use os-level thread oversubscribing
| os level thread | 4 | 8 | 32 | 64 | 128 |
|---|---|---|---|---|---|
| execution time | 0.0029 | 0.0042 | 0.0106 | 0.032 | 1.786 |
We can see that there are not benifits to increase the os-level thread number, since we use the compute intensive tasks, and the core is always busy, if we increase the thread number, it just increase the burdern of the cpu.
Similarly, if we fix the os-level thread as 4 and increase the task processed by user-level threads
| task number | 128 | 256 | 512 | 1024 |
|---|---|---|---|---|
| execution time | 0.0029 | 0.0034 | 0.0040 | 0.0065 |
It is obvious that there is better performance for using the user-level thread.
Generally speaking, the key of the user-level thread is to always keep CPU in busy states. For the process states, it always trys to make process in a running or runnable state. Pthread can switch between multiple different user level thread or tasks.
golang example
Those concepts such as thread pool or user-level light weighted threads and user defiend thread might not that much fancy for the golong programmer. It may be viewd as a standard thing in the golong world. Just review those concepts in golang and try to see some differences here.
This might be a good article to follow (https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html)
From the flexibility, I may say that the golong is successful to be commercialized and it is become the corestone of the cloud computing world. For the thread pool we discussed previously, it is only important in the area of the HPC or scientific applications.
From the technique’s perspective, for the task queue, there are not much difference, both argobot and go scheduler can use the local or global level task queue. For the abstraction, obviously, go version is easy to understand, P represents the abstraction that mapped onto the os-level thread (M), the particular task is wrapped by the goroutine (G). Multiple discussion flcuse about the work stealing algorithm. For the argobot, there are more ditails and API about the abstractions.
This might be an differnet point thought between the research projects and the comertial projects, one need to provide more details and API (instrument point), another is to implement a good wrapping and friendly use semantics.
related code for evaluation
os-level thread oversubscribing
#include <iostream> |
user-level thread server (we need to use server-client pattern in order to use the user level task sleep)
#include <iostream> |
client
#include <iostream> |
other references
how to optimize the thread pool and integrate it with openmpi
a good and very solid work
https://www.openmp.org/wp-content/uploads/SC19-Iwasaki-Threads.pdf
