这几天回想起来defense之后,advisor以及committee member说的congratuation之类的话,总觉得不够真实。心里有时会问问自己,这就结束了,真的结束了吗?
不太想写那种流水账一样的心路历程,大致记录一些当前的思考。整个phd学习的过程和大多数其他同学一样,算不上顺利,开始的两年找不到方向,和别人的合作也不算愉快。之后机缘巧合,遇到了能在具体方向给一些实际指导作用的collebarator,硬着头皮勉强发了几篇论文,凑够了毕业要求,没有很多的功劳和切切实实的contribution,但是总算是有一些苦劳吧,课程完成也算是兢兢业业,最后还要靠一些运气,比如老师催促着想让赶紧毕业,总算是按时完成了毕业要求。
想想看,这几年对于划水这个词似乎有了更深刻的了解,有的时候也不是说自己想划水,大概是客观情况下的一种折衷。看到很多人说自己之前的经历,phd阶段更多地是做一些solid但是不太novelty的工作,自己也有一点类似,有时候只能通过一些苦劳让reviewer觉得这个work还可以勉强接受。
就像面试的时候资历深的researcher所说的,从学生的角度讲,get some ideas and publish papers quickly 这样是好的,但是从researcher的角度上讲,你要关注right problem 而不是fake problem。其实越是资历深的research越是容易怀疑当前做的东西是不是一个fake problem。
答辩结束的几天,看见in-situ这个词就有点反胃,过几天才能安静下来整理一些思路。特别是弄完thesis,真的是不想再看一遍。这也从侧面说明了自己做的这些work整体的质量一般般。
但是安静下来,又想着还是要有点责任心,沉淀沉淀一些核心的想法和问题,看看以后做相关的事情怎么能更有意义一些。
About the target and the platform
关于target以及platform的事情事比较tricky的,好多时候自己说的事情和别人认为的事情不是一个事情,特别是对于in situ worklfow这个词的理解,随着不断投稿然后得到reviewer的feedback,对于这个词的理解才逐渐变得深刻。
首先是对于in situ的定义,这个词在不同的target platform都可以使用,比如在edge device 或者是 observatary facilities都可以使用 in situ 的方式,在论文里说的时候,最好是强调一下这里主要关注的是hpc platform 上处理simulation data 的场景。事实上相关的terminology的论文中的表述都是比较严谨的,比如 这里 直接就是使用的是 in situ analytics and visulization的表述,说的很明确。
还有一个就是关于scientific workflow的表示,这个就更general了,每次想说workflow的时候就需要仔细想想,这里是否有必要用到这个workflow。就算是在scientific 的context 下,常见的workflow都包括这么几种,一个是pegsus compose起来的那种workflow,有比较复杂的task之间的depedency 有点和big data 的平台结合起来的意思,典型的就是Montage的workflow,这种workflow的一个特点就是run application one by one in sequence,一个stage运行完成结束之后才能开始运行下一个stage,典型的就是visulization的pipeline,这一步的results生成之后才能作为输入处理下一步的resutls, the start time of each task depends on the completion of all its predecessors。这里in situ processing 有所区别的地方是,sim 和 vis 是同时在一起运行的,还不停地互相传递着数据。还有一个是那种coupled simulation workflow,就是两个simulation要 互相使用对方的数据,还有一个就是 使用 analytics 和 visulization 来处理simulation的数据的这种workflow,这个才是我们一直比较关注的,所以最好能直接描述准确,比如就使用in situ ana/vis 这样的表述。更不要说其他各种各样的workflow了,比如ensemble workflow以及deep learning的 training workflow 等等,每一种说的都不是一个事情,所以能使用比较准确的词尽量用准确,在论文中的abstract或者introduction部分,多花几句话把这个相关的scope表述清晰也是很有必要的事情。
Motivation of in situ processing
in situ的 main motivation 是 gap between computaion and IO 然后数据量很大,这时候disk IO就是瓶颈,然后很大量的data没法写到disk上来分析,或者IO的时间过长了,需要做analtyics before doing the file IO
但是事实上许多paper里面的用例和规模都没有达到这种IO是bottleneck的程度。不论是从scale上还是数据的量上。可以说大部分的时候in-situ是没有什么必要的,或者说作用不是很大。用一些快速的IO设备比如NVRAM等等,也是能提高速度的。这就是为什么ADIOS主要关注的是file based IO的格式,其他的就是也提供,但是并不是使用的那么广泛。好多时候论文里用到的例子甚至是workflow,实际的bottleneck并不在IO上面,还是computation和analytics,这样来看的话,整个worklfow在这种情况下的优化的重点还确实不是IO.
最初说gap的时候是从整个系统的角度来说的,但是落实到具体的每个应用上,并不一定能把整个系统的computaion能力充分运用起来。比如一些toy problem,几十个节点的规模,其实用in-situ并不是很有必要,虽然确实比disk io快一些,但是并不是非要这样用不可,streaming的处理方式肯定是牺牲了一些数据的持久化和交互的便利性。
但事实上在research paper中,仿佛不提in-situ就不太行,缺少卖点,但是提了之后,又不是那么给力,比如有好多科学家并不认为in-situ能给他们提供多少实实在在的帮助,不仅技术实现上复杂又容易出错还不好debug。甚至包括一些资深的大佬也有这样的argument,确实这是事实情况,这就让新人有点左右为难的感觉。总体上所做的内容和motivation不怎么匹配,所以具体内容研究起来就很矛盾。
从I/O的角度上来讲,in-staging又不是特别有必要,甚至大佬之间对于这个staging based data transfer也是很有争议的一个事情,自己作为新人探索这几年,反而增加了更多的疑惑。甚至有的时候自己对于自己说的东西都有点牵强,也没有办法,但是这个就像是命题作文一样,需要在make sense的方向和导师的interests以及funding的来源上找到一个比较好的交集。
从staging本身最初的起源来看,还是作为那种coupled simulation之间互相share数据的场景比较稳妥,就是caching机制,然后有比较清晰的get和put的interface。
那最终的问题是,什么样的情况下in-situ是必要的呢?一些实际问题中的baseline是什么情况呢? 不涉及一些非技术因素的话,可以参考这个 数据量的话大概是每秒大概要几十GB的规模吧,总之就是满足,如果不用in-situ,就确确实实写不下数据,这么一个情况。这个也是几年前的数据,in general,从workflow的角度来看,要看IO是否是一个比较明显的bottleneck。如果这个overhead相比较sim和ana的区别并不是很显著,那使用in-situ的意义也不是很大,因为引入了很多额外的overhead.
用high performance visulization的书中的话(15.4.1.1),Indeed, because data reduction must occure in the scientific analytisi pipeline in extreme-scale computing(because of the IO gap issue mentioned above), only during the simulation will all relevant data bout the simulated field, computational domain, and related fields be avalibale at the highest fidelity. This scenario is key to in situ processing — that data must be intelligently reduced, analyzed, transformed and indexed while still resident in memory before leaving the machine (or the same system).
当然从research的角度上讲,单纯从方法本身来看,tightly coupled in-situ用来做reduction还是比较好的场景,能确实减少一些IO的overhead. 使用loosely coupled in-situ的意义似乎不是太大,这里的data consumer直接是visulization code比较合适。就像是colza里使用的那种场景。相当于是sim作为source,vis直接作为consumer这样使用。
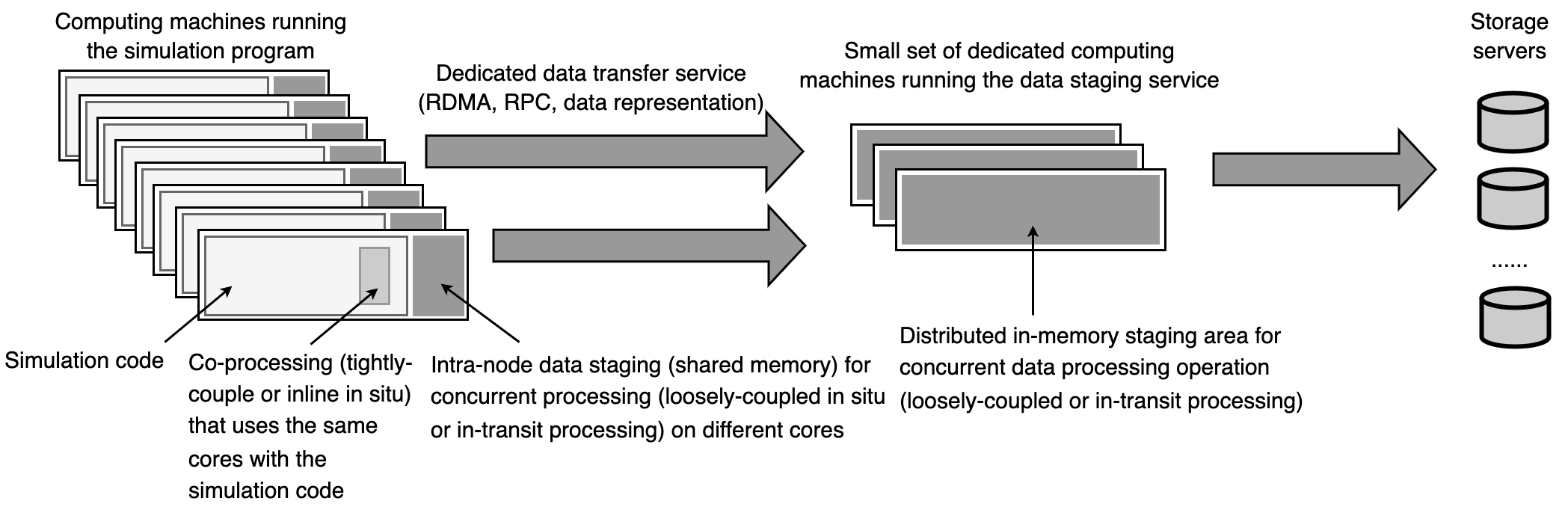
这个图是参考的这本书 (这本书还是比较推荐的):
High performance visualization: Enabling extreme-scale scientific insight[M]. CRC Press, 2012.
里面的Figure 9.6更新了一些相关的term,怪不得大佬说这10多年这个research area都没有多大的进展,其实确实如此,拿出来这个图来看,确实发现和现在相比是没有很多的变化,这个图可以作为以后给别人讲相关work时候的一个background部分,感觉这个表达方式相比于纯粹的文字要清晰很多 (特别是介绍两种具体的loosely-coupled的实现方式的时候,一种on-node一种off-node)。有了这个图作为铺垫,再讲一些后续的工作就比较自然,比如这么多的地方可以执行analytics,放在哪里执行比较有合适,然后dedicated computing machines的elasticity的问题,以及合适传输数据处理数据,trigger analtyics的问题等等。
最近还发现一个图描述的比较清楚,就是这个 paper中的figure: (SIM-SITU: A Framework for the Faithful Simulation of in-situ Workflows, e-science version)
除了之前说的data amount大到一定程度,不得已要使用in-situ之外,书上还介绍了一些其他的in situ的适应场合。”In situ vis is most approporiate when end users know what they want to look in priori” 这个和实践的结果类似,根据自己最近的一些经验,通常是使用post processing把需要弄的内容处理好,比如使用paraview catalyst调整好一些合适的参数和view,之后把这个操作固定下来,按照一个template的方式integrate到in-situ的pipeline中。或者是in-situ的方式进行一些数据的preprocessing,仅仅保留一些对于post-processing有用的数据。
因为data exploration的过程通常是很久的并且这些时间难以预料,domain scientists需要很多时间来分析,所以data exploration本身不太适合使用in-situ的方式来进行,这也就是post-processing必不可少的地方。所以大致流程是 post processing 和 in-situ processing 交替进行的过程,post-procesisng 得到一些knowlege,然后in-situ processing 筛选出新的数据,然后再 post-processing 这样反复进行。从这个角度来看,in situ 和 post processing 似乎是在一个轴的两端,一个是有很好的speed improvement但是不够flexibility另外一个是很好的interaction但是speed不太行。 只是从avalibility的角度看insitu,或者是streaming processing的一个例子。
Tar pit about in situ
In situ is just a way to do things, 如果把research的重点放在是不是一个方法要用in situ来运行或者in situ 到底有没有意义这种,显然就容易走火入魔,觉得自己想了很多,但是似乎也什么都没想,仿佛是在原地踏步或者原地绕圈,十分危险,因为很显然in situ 并不是 silver bullet,很多场景下也并不适用,回答说in situ 有用或者in situ 没有,都能举出很多反例。从论文的角度讲就是找一个适用的场合。Research 的重点还是在比如visualization, data compression, data refactor + index, data transfer, 或者是 resource management 等等这些比较具体的事情上。重点放在这些事情本身上就不容易迷路,至于具体是不是in situ,其实总是可以往上面结合的,结合也行不结合也行。想想成功的例子,就比如vtk这一系列,在各个场景中都可以使用。在不同场景下侧重点不一样,这样就是比较成功的story。比较危险的就是workflow optimization,具体是哪种workflow这一定要先仔仔细细考虑清楚或者说明清楚,一个workflow有一个workflow的适用场景,在一个场景下讨论另一个场景的solution仿佛是如同鸡同鸭讲。
Data reduction or refactor and complex workflow
来到新的组里,虽然还是做的in situ相关的事情,但比较强调的是这两个方面。data reduction or refactor 显然是针对big data的一个典型的场景,除了说 in situ 的处理数据外,从数据流的入口处就应该尽量的refactor data 比如取一些 quality of interest 的内容,或者是interesting的pattern,等等。这也就是体现了为何lossy compression一直比较火的原因。但是整体来看还是需要和应用相关,因为这样才知道什么是可以loss处理的地方,什么是不需要loosy的地方。从loosy compression的角度来看,最好能提供这样的交互,让compression的地方变得更智能化一些。
另外一个就是比较naive的了,就是关注complicated的workflow,而不是仅仅的simulation-visulization 的workflow。这个时候in situ本身就变得不重要了,或者是部分in situ 就好,总而言之这两个方向要是想做出比较好的research还是要和实际的workflow或者应用的场景紧密结合起来才比靠谱,否则就又是一个自己设想的实际状态中可能不存在的场景了。
Tightly coupled vs Loosely coupled, which is better
对于这个问题从技术的角度上看,整理的比较好的就是这一篇
Kress, James, et al. “Loosely coupled in situ visualization: A perspective on why it’s here to stay.” Proceedings of the First Workshop on In Situ Infrastructures for Enabling Extreme-Scale Analysis and Visualization. 2015.
loosely 和 tightly 是两种方式 (or inline insitu and in-transit),具体什么样的方式比较好肯定是根据具体的使用场景而言的,在一些视频中也有提到 (比如这个 https://www.youtube.com/watch?v=uKaDNW-2m40 19:55的地方)
关键在实施或者做事的过程上,大家并不全是按照技术的角度来处理问题,比如老师的funding如果有的时候来自于某一个具体的项目,这个时候就binding在这个项目相关的技术方向上了,就比如我自己的经历,基本上是我们这个组的所有的research都是在做in-transit相关的,这就导致了论文里好像有时候并不足够客观,reviewer可能有时候就会问,为什么用这个方式不用那个方式?用这个方式的好处在哪里?这种问题有时候很难回答,因为可能两种方式差不多,或者使用某种方式其实不是特别有必要的,但是由于一些非技术的因素,让你使用了某个特定的方式。
从赶快出成果的角度讲,这种时候自己就选择了一个范围更广的课题,能把这两种方式都包含进来,这样从技术的角度和非技术的角度都是一个交代。
但确确实实还是应该更加实事求是一些,看看自己的应用场景是否和使用的相关技术比较匹配,这样更convincing一些。
比较主流的一种思路就是从cost的角度分析,比较好的还是James的这一篇:Opportuniteis for Cost Savings with In-Transit Visualization
这里build model 采用了两个比较好的思路,一个是把所有的时间变成了比例,这样所有用到sim的地方就变成了1,其他的地方,比如vis的时间,就变成了vis想比于sim所消耗的时间的比例,这样表示就很大程度上地简化了方程的表达式。
还有一个思路是用 Tsim+Tblock 来表示sim所花费的时间,这样Tblock为0的时候就vis完全比sim花费的时间短了。之前常常使用的是 max {sim,vis} 这种表述,使用max的这种表述就是不太灵活。
The lack of application scenario and actual data
开始的时候无从下手,直到有了gray scott的sim的code,说起来都是一些简单的sim,但是作为一些proof of concept的项目也足够了。
这一块儿归根结底还是要figure out workflow到底是什么。就算thesis的writting,前几章的motivation也还是关于workflow以及相关的requriements的描述。
More concrete research domains
之前的选择的topic其实是属于相对简单一些的,比如in situ的那些topic,基本上稍微看一下都知道怎么回事,但是想继续在相关的领域有所发展的话,还是需要做一些更细致的内容。比如IO,compression,reduction或者是vis的pipeline。从vis的角度来看的话需要更关注的就是vis本身的pipeline,然后这个pipeline是怎么和insitu的pipeline结合起来的。
比如这个文章里面的图强调的几个stage,importing,filtering and enriching,mapping以及最后的rending。
从vis的pipeline的角度来看,它就是另外的一个research domain了,这个research domain的重要应用是和in situ processing 结合起来。因为in situ processing 本来只是一种architecture,并不是说非得按照这个方式来进行,相当于是一种形而上的方式,如果说research domain是in situ processing 就不太能走长远,再泛一点大致算到是workflow的研究领域。总之要有一个相对更solid的领域,更通俗一点说,就是关注方法上的一些改进,比如做这个事情,可以按照insitu的方式,也可以不按照insitu的方式,具体做的内容也不会受限于当前的技术,反而是根据技术的发展不断改进和提升。
Scratch
从理解的角度上讲,和别人在专业的问题上进行交流的时候,对于语言和思维的把控上还是不行,如果别人一下子说一大段话,就有点脑子发懵,或者问相关的问题,有点跟不上节奏,可能是对于英语的解析能力还是有限。
付出了一些时间,甚至牺牲了一些健康,还是挺想做正确的事情的,到最后发现只是make a living。
或者就是从vis的角度出发,采用都不得罪的办法,比如一个新的点,然后用tighly-coupled实现一下,用loosely coupled 实现一下,这个样子。
今天参加了学校举行的hooding process,和别人说起来也算是知道这个hooding ceremony是怎么回事儿了,中文翻译成为博士披肩似乎是比较make sense的表述,本科时候的毕业的仪式是拨穗。感觉还是挺有仪式感的,亲戚朋友过来一起庆祝毕业还是一个挺有意思的时候。如果老师能过来hooding process就真的是很nice了,整个上午的时间每个人hooding的时间只有那么几分钟,老师要是能抽空过来那真的是对于学生来讲有很大的纪念意义了。不过听台上讲话的人讲东西的时候有些心不在焉,只顾着在纪念册上找自己的名字,似乎没有留下很多能和别人分享的记忆点。
Software about the loosely coupled in situ
至于 loosely coupled in situ,实现的时候绕不开的就是 through high speed networking between different nodes and differen programs 常见的就是ADIOS以及Mochi service。从灵活性上讲, mochi service 显然是更胜一筹了。从实用性上讲,ADIOS和simulation本身的数据结合的更紧密一些,就是更偏向于工程化了。底层的networking层都是利用的libfabric,mochi 是基于margo以及argobot的这种底层多线程的服务,所以构建staging service的时候显然更方便一些。从research的角度讲,如果论文中提到了loosely coupled data staging service,那这两个服务是无论如何都绕不开的了。
Challenges in the domain of the in situ processing
在面试的时候被问到一个问题“what are most research challenges in the domain of in situ processing” 从国内以及国外两个角度回答。
我的答案大致是
1 in stu 本身已经有了十多年的研究历史,很多方案已经成熟,在一些比较好的杂志上关于in situ的主题逐渐减少。
2 如何与新的方法结合是比较重要的挑战。
3 如何让这些方法或者解决方案能在更广泛的场景下(脱离了已有的场景)发挥作用是比较大的挑战。
4 在国内的话可能如何利用新的加速器是一个比较大的挑战。
这些说的大致都没错,但后来评委老师反馈,这个回答给老师们留下的映像不是太好,比如第一个说的,有一种让自己说的泄了气的感觉。
TODO
首先是最重要的motivation 然后举出来几个例子 解决了一部分 还在解决的是什么 到in situ reduction的地方
然后说in situ的一些解决方案
然后说当前的共同挑战
针对国内国外的特点
各有特色地说一说
post hoc in situ
这个表述是chatgpt生成的,主要就是针对那种使用了post hoc的方式,但是数据并不出去本计算系统的visualization的方式。比如说具体很典型的post hoc就是数据在HPC上产生,之后transfer到本地的计算资源,比如本地的local workstation上,然后再做visualization,这整个过程中涉及到了两个计算系统。那所谓的post hoc in situ就是数据不出HPC系统,直接在远程的HPC平台上做一些可视化的操作。这个和传统的post hoc的区别就是数据不会download到本地,和tightly与loosely coupled的区别就是数据还是显示的存储出来的。在数据access的层面上是off node access data 的方式。其实本质上来说可以算是一种远程可视化,因为总是要查看可视化的结果的,可视化的结果总需要通过web或者是定制软件传递到本地的设备上来进行查看。
